
Python爬取小说
介绍
使用python搜索天天看小说站内的书籍,获取对应章节及正文,用MySQL保存书名及章节数以便下次继续观看,再使用streamlit制作web,将获取到的小说打印出来。
依旧是不懂的、报错的问chatgpt😇
天天看小说:⚡ 天天看小说 (ttkan.co),几乎没有什么广告,挺好的一个网站,就是需要翻墙
预览
先注册一个ID,分开用户的阅读进度。
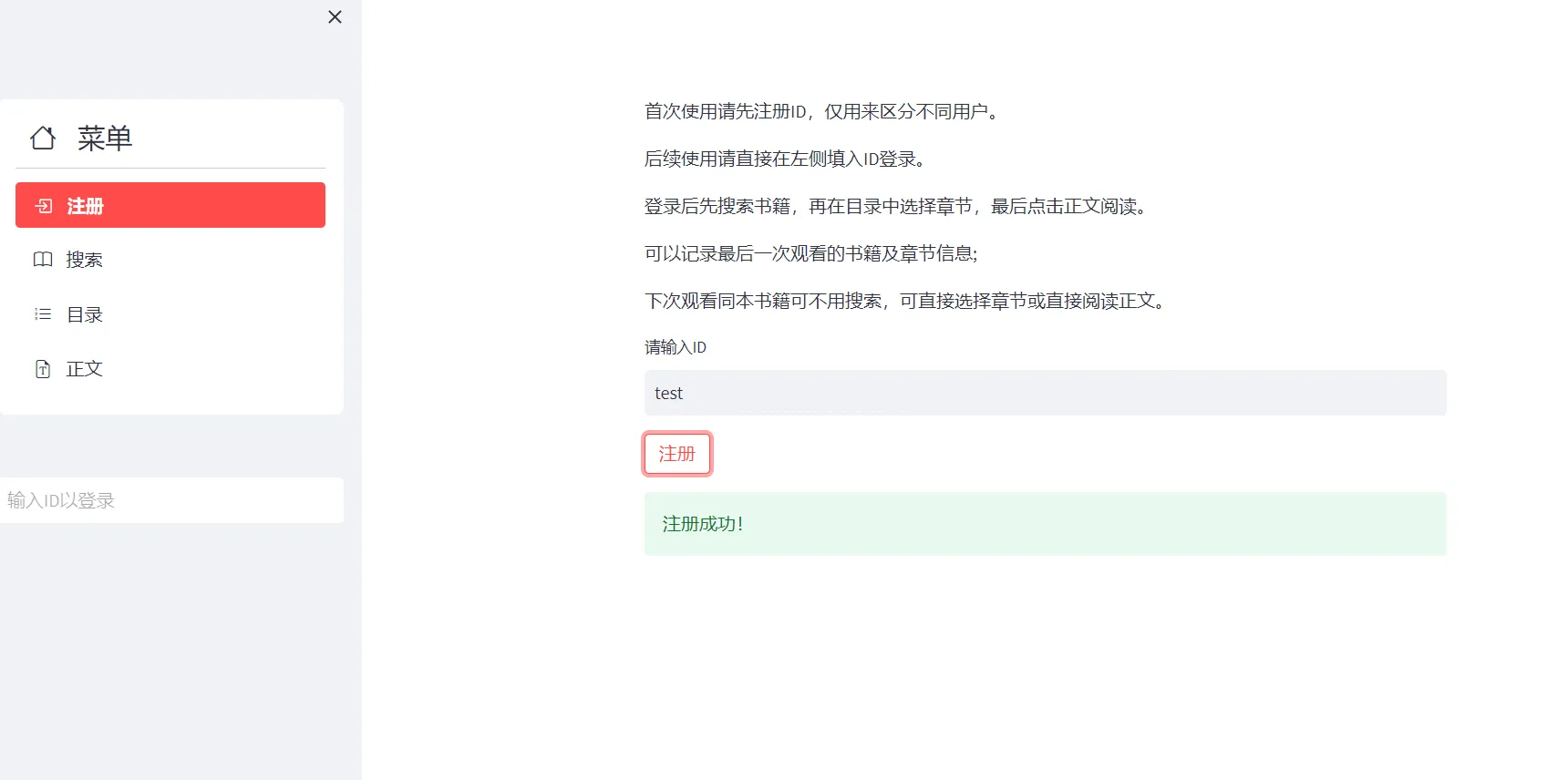
已存在ID提醒更换

未登录不可以看书

侧边栏黑框处填入ID登录,先搜本书
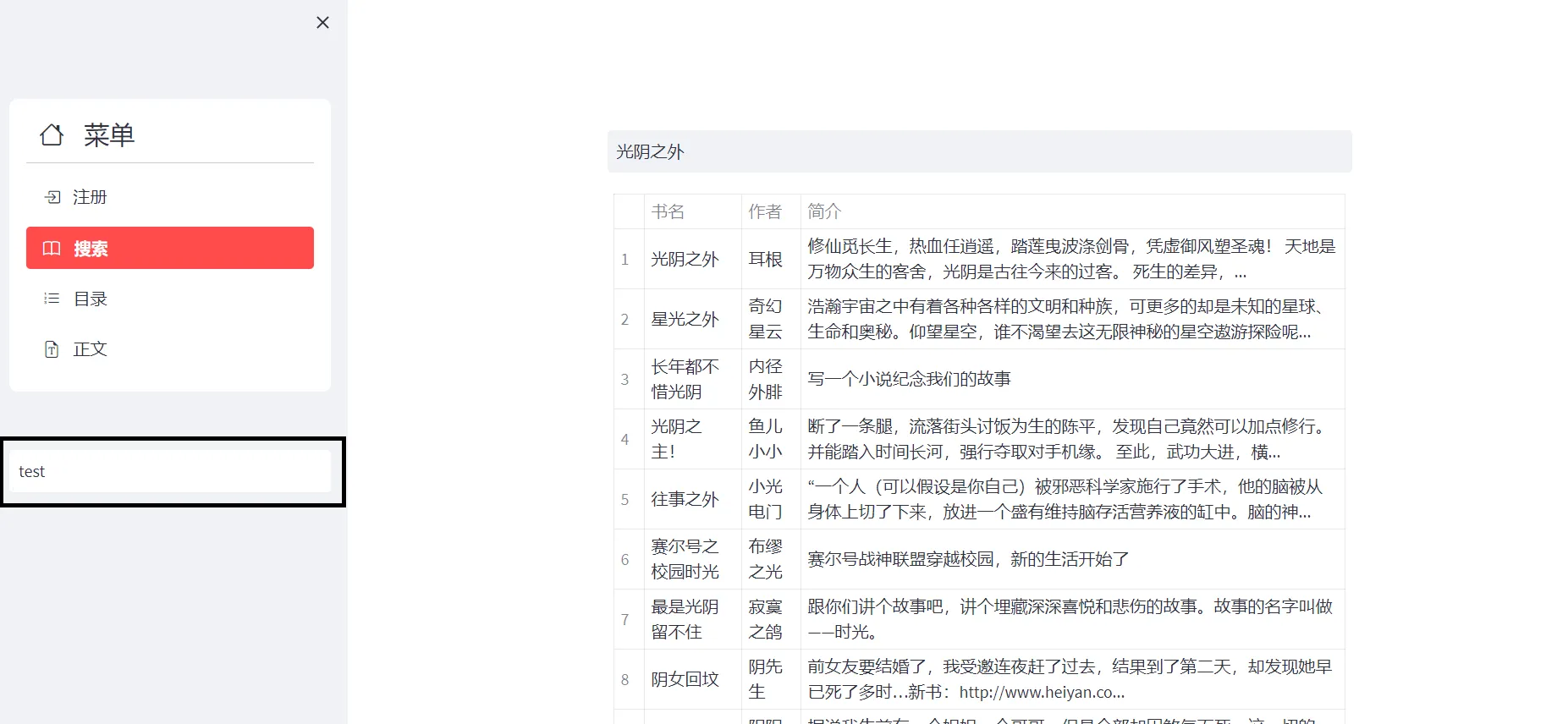
往下滑滑选一本书,默认第一本
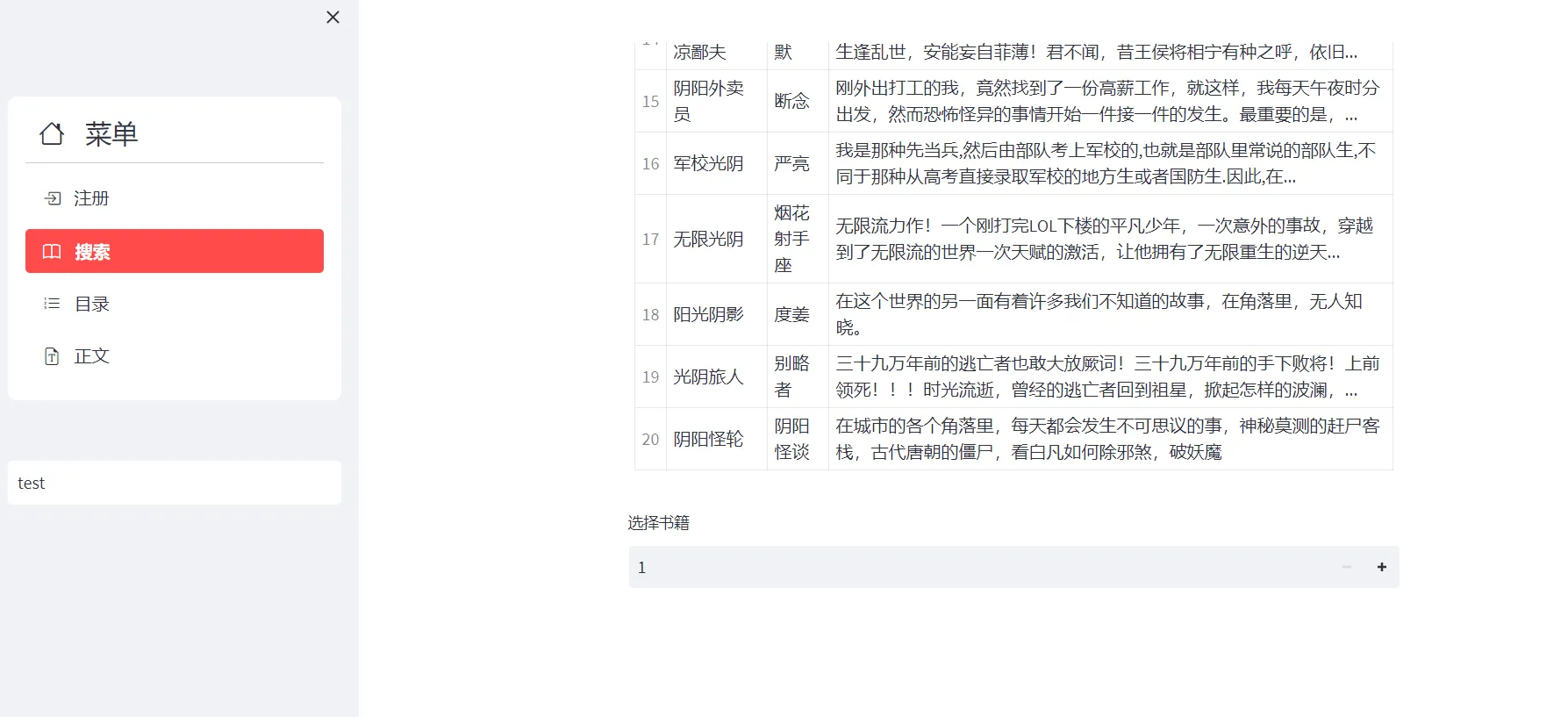
如果跳过搜索阶段会提示
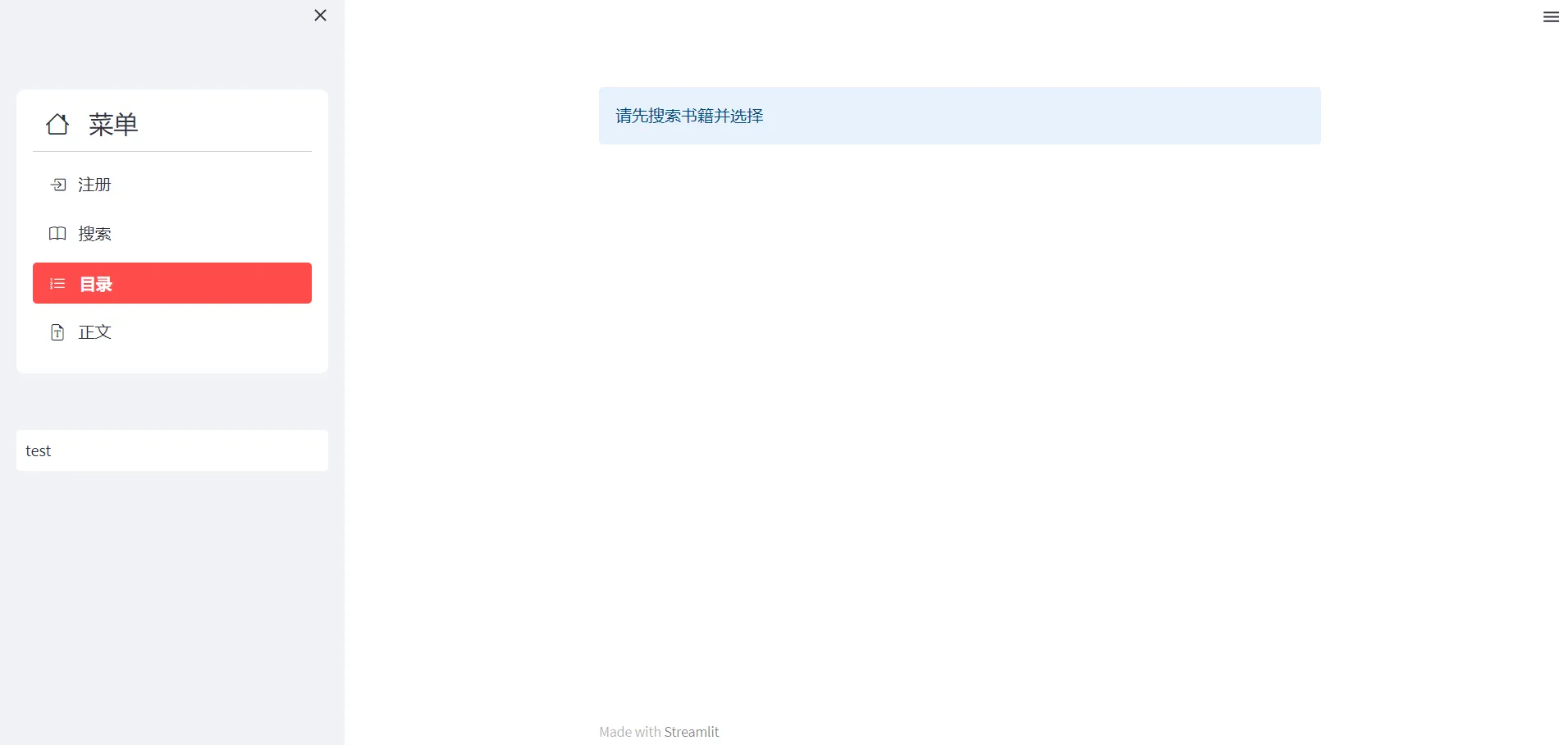
选好书后点击目录选择章节,章节与索引不是完全对应的,后面会用索引来爬对应章节,不要填章节内的章节数。
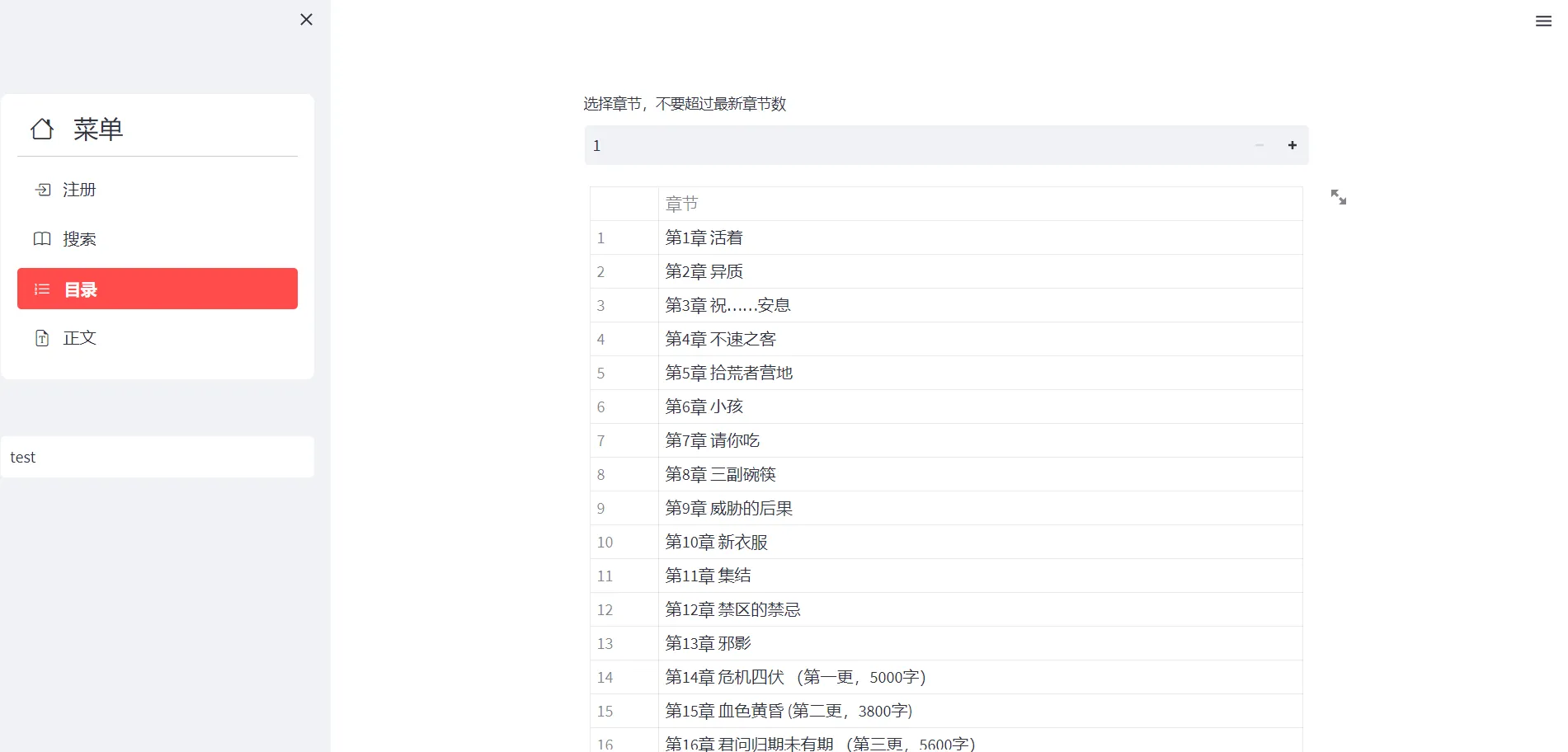
最后点击正文,因为有的正文,没有标题,所以每篇都先打印当前章节名,再打印文章。

最后有两个按钮,前往上一章节和下一章节,但不能自动翻到顶部,要手动滑到顶部从头观看,不会搞,就这样吧🤡

代码
需要一个数据库,python要安装好streamlit,BeautifulSoup,pandas,streamlit_option_menu库
streamlit run app.py 运行程序
nohup streamlit run app.py & 后台运行
import requests
from bs4 import BeautifulSoup
import pandas as pd
from streamlit_option_menu import option_menu
import streamlit as st
import pymysql
# 建立数据库连接
# 先建一个streamlit数据库,添加log_in表,添加id、chapter、book_id三个字段,上面的名字可自定义,字段varchar类型,长度随便设个50,不能太短
def db_coon():
conn = pymysql.connect(
host='主机名',
port=端口,
user='用户名',
password='密码',
db='streamlit'
)
cursor = conn.cursor()
return conn,cursor
# 爬虫
class Worm():
def __init__(self):
self.api_url = 'https://cn.ttkan.co/api/nq/amp_novel_chapters?language=cn&novel_id=%s'
self.search_url = 'https://cn.ttkan.co/novel/search?q=%s'
self.read_url = 'https://cn.bg3.co/novel/pagea/%s_%s.html'
self.headers = {
'user-agent':'去网站F12自己复制'
}
#搜索书籍,返回前二十本书籍
def search(self,book):
book_names = []
book_links = []
book_authers = []
book_intros = []
response = requests.get(self.search_url % book,headers=self.headers)
soup = BeautifulSoup(response.text,'html.parser')
books = soup.findAll('div',class_= 'pure-u-1-1')
for book in books:
book_name = book.find('h3').text
book_names.append(book_name)
book_link = book.find('a')['href']
book_links.append(book_link),
book_sth = book.find('ul').text
author = book_sth.split('作者:')[1].split('简介:')[0]
intro = book_sth.split('简介:')[1]
book_authers.append(author)
book_intros.append(intro)
book_names_20 = book_names[:20]
book_links_20 = book_links[:20]
book_authers_20 = book_authers[:20]
book_intros_20 = book_intros[:20]
data = {
'book_name':book_names_20,
'book_link':book_links_20,
'book_authers':book_authers_20,
'book_intro':book_intros_20
}
data_view = {
'书名':book_names_20,
'作者':book_authers_20,
'简介':book_intros_20
}
book_df_view = pd.DataFrame(data_view,index=range(1, 21))
book_df = pd.DataFrame(data)
# 返回两个表,一个后面打印到屏幕上,一个通过索引获取小说链接
return book_df,book_df_view
def open_url(self,url):
response = requests.get(url, headers=self.headers).content
response_decoded = response.decode('utf-8')
return response_decoded
# 获取目录
def get_list(self,book_id):
response = requests.get(self.api_url % book_id,headers=self.headers)
novel_chapters = response.json()['items']
chapter_ids = []
chapter_names = []
for chapter in novel_chapters:
chapter_name = chapter['chapter_name']
chapter_names.append(chapter_name)
chapter_id = chapter['chapter_id']
chapter_ids.append(chapter_id)
# 这边脑抽了多此一举,我也不想改了
data = {'章节':chapter_names}
data_view = {'章节':chapter_names}
chapter_df_view = pd.DataFrame(data_view,index=chapter_ids)
chapter_df = pd.DataFrame(data)
return chapter_df,chapter_df_view
# 获取正文
def get_txt(self,book_id,chapter):
response = requests.get(self.read_url %(book_id,chapter),headers=self.headers)
soup = BeautifulSoup(response.text,'html.parser')
txt = soup.findAll('p')
text = [p.text.strip() for p in txt]
return text
# web
class Streamlit():
# 网页title和icon
st.set_page_config(
page_title="阅读",
page_icon=":book:"
)
# 侧边栏搞4个板块,再获取ID变量
with st.sidebar:
selected = option_menu("菜单", ['注册', "搜索", '目录', '正文'],
icons=['bi-box-arrow-in-right', 'bi-book', 'bi-list-ol', 'bi-file-earmark-font'],
menu_icon="bi-house", default_index=0)
id = st.text_input('', placeholder='输入ID以登录')
#注册板块,附带使用教程
if selected == "注册":
st.write('首次使用请先注册ID,仅用来区分不同用户。')
st.write('后续使用请直接在左侧填入ID登录。')
st.write('登录后先搜索书籍,再在目录中选择章节,最后点击正文阅读。')
st.write('可以记录最后一次观看的书籍及章节信息;')
st.write('下次观看同本书籍可不用搜索,可直接选择章节或直接阅读正文。')
id = st.text_input('请输入ID', placeholder='不限制输入类型和长度,可以是数字、汉字、字母')
if st.button('注册'):
conn,cursor = db_coon()
sql_query = "SELECT * FROM log_in WHERE id = %s"
cursor.execute(sql_query, (id,))
result = cursor.fetchone()
if result:
st.warning("该id已存在,请更换id")
else:
sql_insert = "INSERT INTO log_in (id) VALUES (%s)"
cursor.execute(sql_insert, (id,))
conn.commit()
st.success("注册成功!")
cursor.close()
conn.close()
# 搜索板块
if selected == "搜索":
sth = st.text_input('', placeholder='斗破苍穹')
if not sth:
st.write('输入完成点击其他地方或回车开始搜索')
else:
book_df, book_df_view = Worm().search(sth)
st.table(book_df_view)
number = st.number_input('选择书籍', min_value=1, max_value=20, value=1, step=1)
if isinstance(number, int):
index = number - 1
book_link = book_df['book_link'][index]
book_id = str(book_link).split('/')[-1]
conn, cursor = db_coon()
sql_query = "SELECT * FROM log_in WHERE id = %s"
cursor.execute(sql_query, (id,))
result = cursor.fetchone()
if result:
sql = "UPDATE log_in SET book_id = %s WHERE id = %s"
cursor.execute(sql, (book_id, id))
conn.commit()
else:
st.warning("请先注册登录")
cursor.close()
conn.close()
# 目录板块
elif selected == "目录":
conn, cursor = db_coon()
cursor.execute('select book_id from log_in where id = %s',(id,))
result = cursor.fetchone()
if result:
book_id = result[0]
if not book_id:
st.info('请先搜索书籍并选择')
else:
num = st.number_input('选择章节,不要超过最新章节数', min_value=1, value=1, step=1)
chapter_df, chapter_df_view = Worm().get_list(book_id)
st.table(chapter_df_view)
if isinstance(num, int):
cursor.execute('update log_in set chapter = %s where id = %s',(num,id))
conn.commit()
else:
st.warning("请先登录")
cursor.close()
conn.close()
# 正文
elif selected == "正文":
conn, cursor = db_coon()
cursor.execute('select book_id,chapter from log_in where id = %s',(id,))
result = cursor.fetchone()
if result:
book_id = result[0]
chapter = result[1]
if not book_id:
st.info('请先前往目录选择章节')
else:
chapter_df, chapter_df_view = Worm().get_list(book_id)
st.write(chapter_df['章节'][int(chapter) - 1])
text = Worm().get_txt(book_id, chapter)
for line in text:
st.write(line)
col1,col2 = st.columns(2)
with col1:
if st.button('上一章'):
chapter = int(chapter) - 1
sql = "UPDATE log_in SET chapter = %s WHERE id = %s"
cursor.execute(sql, (chapter, id))
conn.commit()
st.experimental_rerun()
with col2:
if st.button('下一章'):
chapter = int(chapter) + 1
sql = "UPDATE log_in SET chapter = %s WHERE id = %s"
cursor.execute(sql, (chapter, id))
conn.commit()
st.experimental_rerun()
else:
st.info('请先注册登录')
cursor.close()
conn.close()
# 装模作样写一个这玩意
if __name__ == '__main__':
Streamlit()
也可以用自带的sqlite3
先创建一个数据库,建好表和字段
import sqlite3
conn = sqlite3.connect('novel.db')
cursor = conn.cursor()
sql = "create table book(id varchar(50),chapter varchar(50),book_id varchar(50))"
cursor.execute(sql)
conn.commit()
conn.close()因为sqlite的占位符是?,所以将程序内和数据库有关的占位符%s换成?。
import sqlite3
import requests
from bs4 import BeautifulSoup
import pandas as pd
from streamlit_option_menu import option_menu
import streamlit as st
# 建立数据库连接
def db_coon():
conn = sqlite3.connect('novel.db')
cursor = conn.cursor()
return conn,cursor
class Worm():
def __init__(self):
self.api_url = 'https://cn.ttkan.co/api/nq/amp_novel_chapters?language=cn&novel_id=%s'
self.search_url = 'https://cn.ttkan.co/novel/search?q=%s'
self.read_url = 'https://cn.bg3.co/novel/pagea/%s_%s.html'
self.headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.68'
}
#搜索书籍,返回前二十本书籍
def search(self,book):
book_names = []
book_links = []
book_authers = []
book_intros = []
response = requests.get(self.search_url % book,headers=self.headers)
soup = BeautifulSoup(response.text,'html.parser')
books = soup.findAll('div',class_= 'pure-u-1-1')
for book in books:
book_name = book.find('h3').text
book_names.append(book_name)
book_link = book.find('a')['href']
book_links.append(book_link),
book_sth = book.find('ul').text
author = book_sth.split('作者:')[1].split('简介:')[0]
intro = book_sth.split('简介:')[1]
book_authers.append(author)
book_intros.append(intro)
book_names_20 = book_names[:20]
book_links_20 = book_links[:20]
book_authers_20 = book_authers[:20]
book_intros_20 = book_intros[:20]
data = {
'book_name':book_names_20,
'book_link':book_links_20,
'book_authers':book_authers_20,
'book_intro':book_intros_20
}
data_view = {
'书名':book_names_20,
'作者':book_authers_20,
'简介':book_intros_20
}
book_df_view = pd.DataFrame(data_view,index=range(1, 21))
book_df = pd.DataFrame(data)
return book_df,book_df_view
def open_url(self,url):
response = requests.get(url, headers=self.headers).content
response_decoded = response.decode('utf-8')
return response_decoded
def get_list(self,book_id):
response = requests.get(self.api_url % book_id,headers=self.headers)
novel_chapters = response.json()['items']
chapter_ids = []
chapter_names = []
for chapter in novel_chapters:
chapter_name = chapter['chapter_name']
chapter_names.append(chapter_name)
chapter_id = chapter['chapter_id']
chapter_ids.append(chapter_id)
data = {'章节':chapter_names}
data_view = {'章节':chapter_names}
chapter_df_view = pd.DataFrame(data_view,index=chapter_ids)
chapter_df = pd.DataFrame(data)
return chapter_df,chapter_df_view
def get_txt(self,book_id,chapter):
response = requests.get(self.read_url %(book_id,chapter),headers=self.headers)
soup = BeautifulSoup(response.text,'html.parser')
txt = soup.findAll('p')
text = [p.text.strip() for p in txt]
return text
class Streamlit():
st.set_page_config(
page_title="阅读",
page_icon=":book:"
)
with st.sidebar:
selected = option_menu("菜单", ['注册', "搜索", '目录', '正文'],
icons=['bi-box-arrow-in-right', 'bi-book', 'bi-list-ol', 'bi-file-earmark-font'],
menu_icon="bi-house", default_index=0)
id = st.text_input('', placeholder='输入ID以登录')
if selected == "注册":
st.write('首次使用请先注册ID,仅用来区分不同用户。')
st.write('后续使用请直接在左侧填入ID登录。')
st.write('登录后先搜索书籍,再在目录中选择章节,最后点击正文阅读。')
st.write('可以记录最后一次观看的书籍及章节信息;')
st.write('下次观看同本书籍可不用搜索,可直接选择章节或直接阅读正文。')
id = st.text_input('请输入ID', placeholder='不限制输入类型和长度,可以是数字、汉字、字母')
if st.button('注册'):
conn,cursor = db_coon()
sql_query = "SELECT * FROM book WHERE id = ?"
cursor.execute(sql_query, (id,))
result = cursor.fetchone()
if result:
st.warning("该id已存在,请更换id")
else:
sql_insert = "INSERT INTO book (id) VALUES (?)"
cursor.execute(sql_insert, (id,))
conn.commit()
st.success("注册成功!")
cursor.close()
conn.close()
if selected == "搜索":
sth = st.text_input('', placeholder='斗破苍穹')
if not sth:
st.write('输入完成点击其他地方或回车开始搜索')
else:
book_df, book_df_view = Worm().search(sth)
st.table(book_df_view)
number = st.number_input('选择书籍', min_value=1, max_value=20, value=1, step=1)
if isinstance(number, int):
index = number - 1
book_link = book_df['book_link'][index]
book_id = str(book_link).split('/')[-1]
conn, cursor = db_coon()
sql_query = "SELECT * FROM book WHERE id = ?"
cursor.execute(sql_query, (id,))
result = cursor.fetchone()
if result:
sql = "UPDATE book SET book_id = ? WHERE id = ?"
cursor.execute(sql, (book_id, id))
conn.commit()
else:
st.warning("请先注册登录")
cursor.close()
conn.close()
elif selected == "目录":
conn, cursor = db_coon()
cursor.execute('select book_id from book where id = ?',(id,))
result = cursor.fetchone()
if result:
book_id = result[0]
if not book_id:
st.info('请先搜索书籍并选择')
else:
num = st.number_input('选择章节,不要超过最新章节数', min_value=1, value=1, step=1)
chapter_df, chapter_df_view = Worm().get_list(book_id)
st.table(chapter_df_view)
if isinstance(num, int):
cursor.execute('update book set chapter = ? where id = ?',(num,id))
conn.commit()
else:
st.warning("请先登录")
cursor.close()
conn.close()
elif selected == "正文":
conn, cursor = db_coon()
cursor.execute('select book_id,chapter from book where id = ?',(id,))
result = cursor.fetchone()
if result:
book_id = result[0]
chapter = result[1]
if not book_id:
st.info('请先前往目录选择章节')
else:
chapter_df, chapter_df_view = Worm().get_list(book_id)
st.write(chapter_df['章节'][int(chapter) - 1])
text = Worm().get_txt(book_id, chapter)
for line in text:
st.write(line)
col1,col2 = st.columns(2)
with col1:
if st.button('上一章'):
chapter = int(chapter) - 1
sql = "UPDATE book SET chapter = ? WHERE id = ?"
cursor.execute(sql, (chapter, id))
conn.commit()
st.experimental_rerun()
with col2:
if st.button('下一章'):
chapter = int(chapter) + 1
sql = "UPDATE book SET chapter = ? WHERE id = ?"
cursor.execute(sql, (chapter, id))
conn.commit()
st.experimental_rerun()
else:
st.info('请先注册登录')
cursor.close()
conn.close()
Streamlit()
结尾
折腾这玩意比打游戏有意思多了🥰
爬的这个网页是要翻墙才能访问的,pc上是全局模式,没注意到,结果放家里的服务器上运行下死活爬不到信息,我还以为是我写的不对又弄了半天,最后发现在家中的服务器ping不通这个域名😅