Python爬虫下载酷我音乐
介绍
学了点python的皮毛,写了个下载酷我音乐的爬虫,用streamlit生成web程序,边写边看文档,看不懂问chatgpt,报错也问chatgpt,做出来的东西还算能用🥰
感谢酷我音乐提供的优质音乐资源
5月3日更新
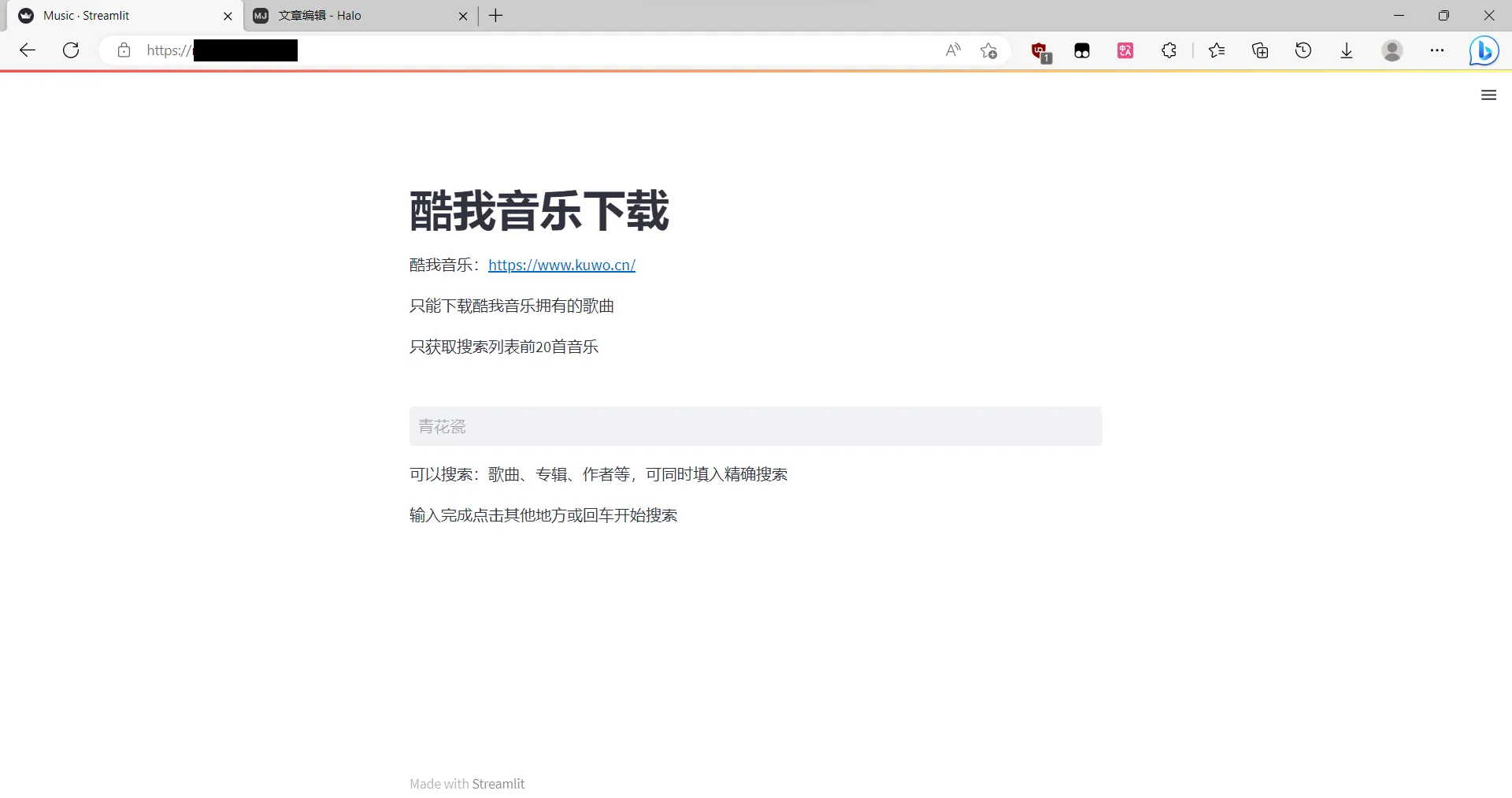
可以搜索歌曲、专辑、作者
至多显示前20首歌曲
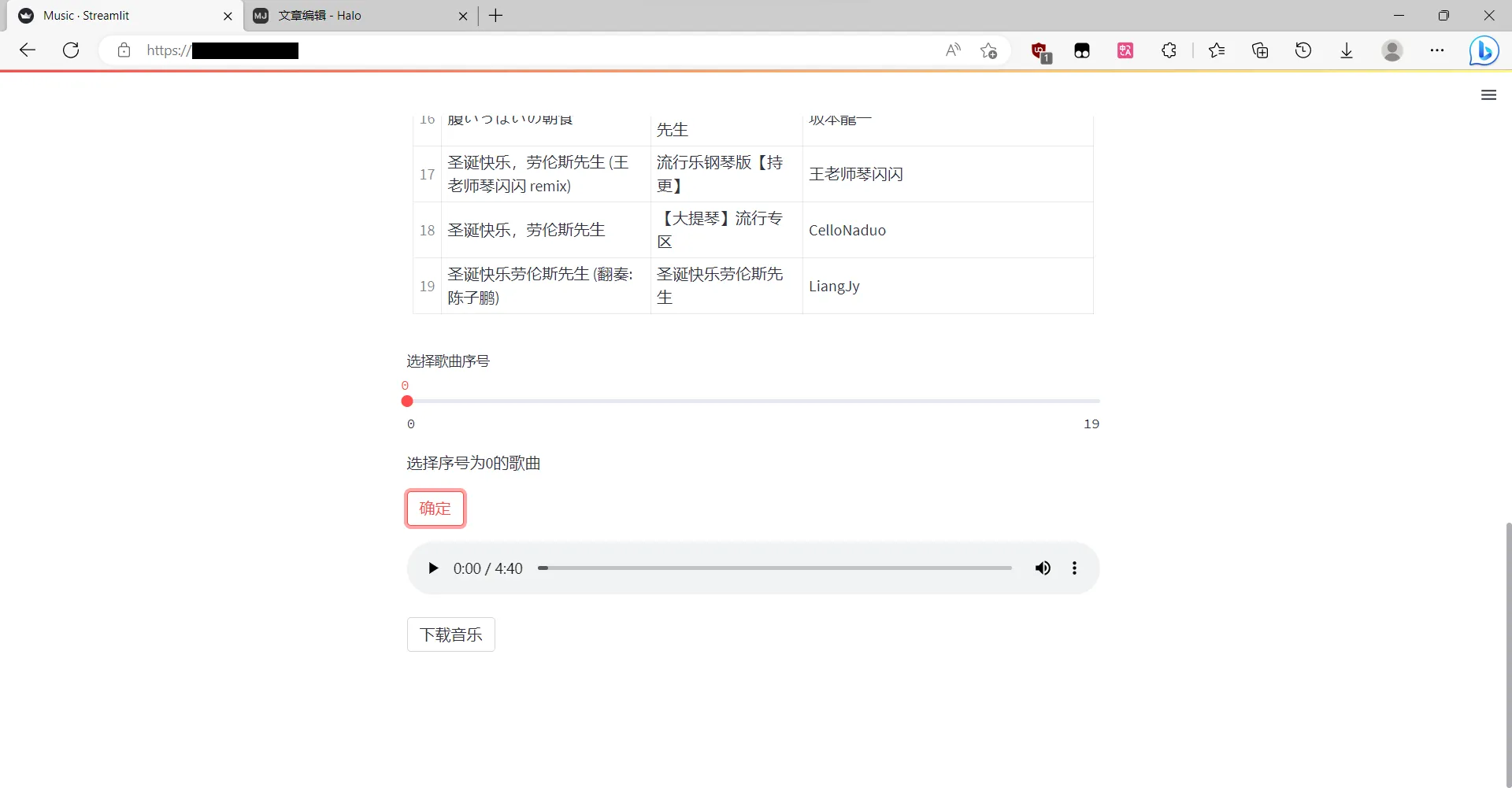
预览
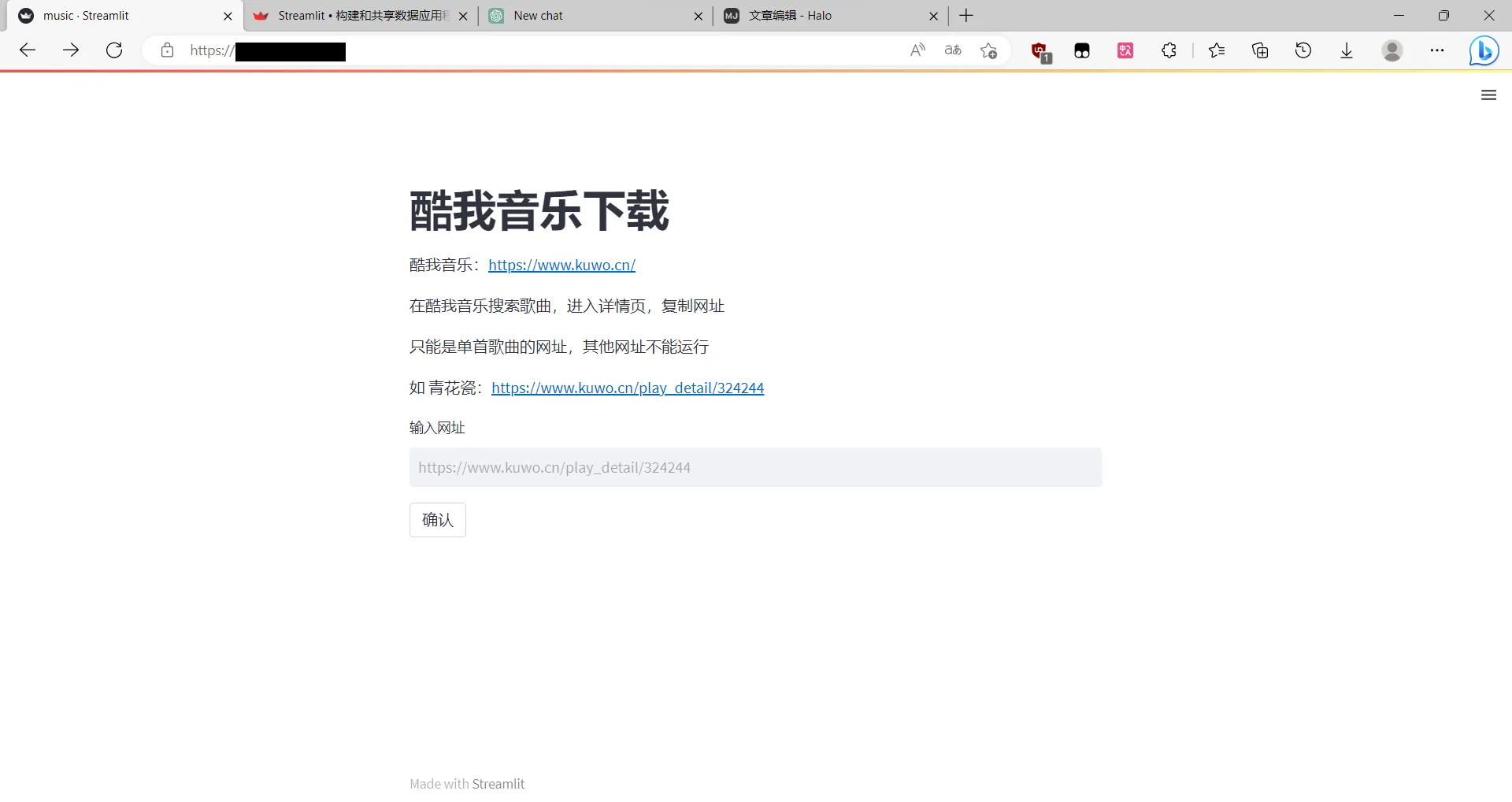
v1.1
填写音乐url点击确认即可下载音乐😋
v1.2
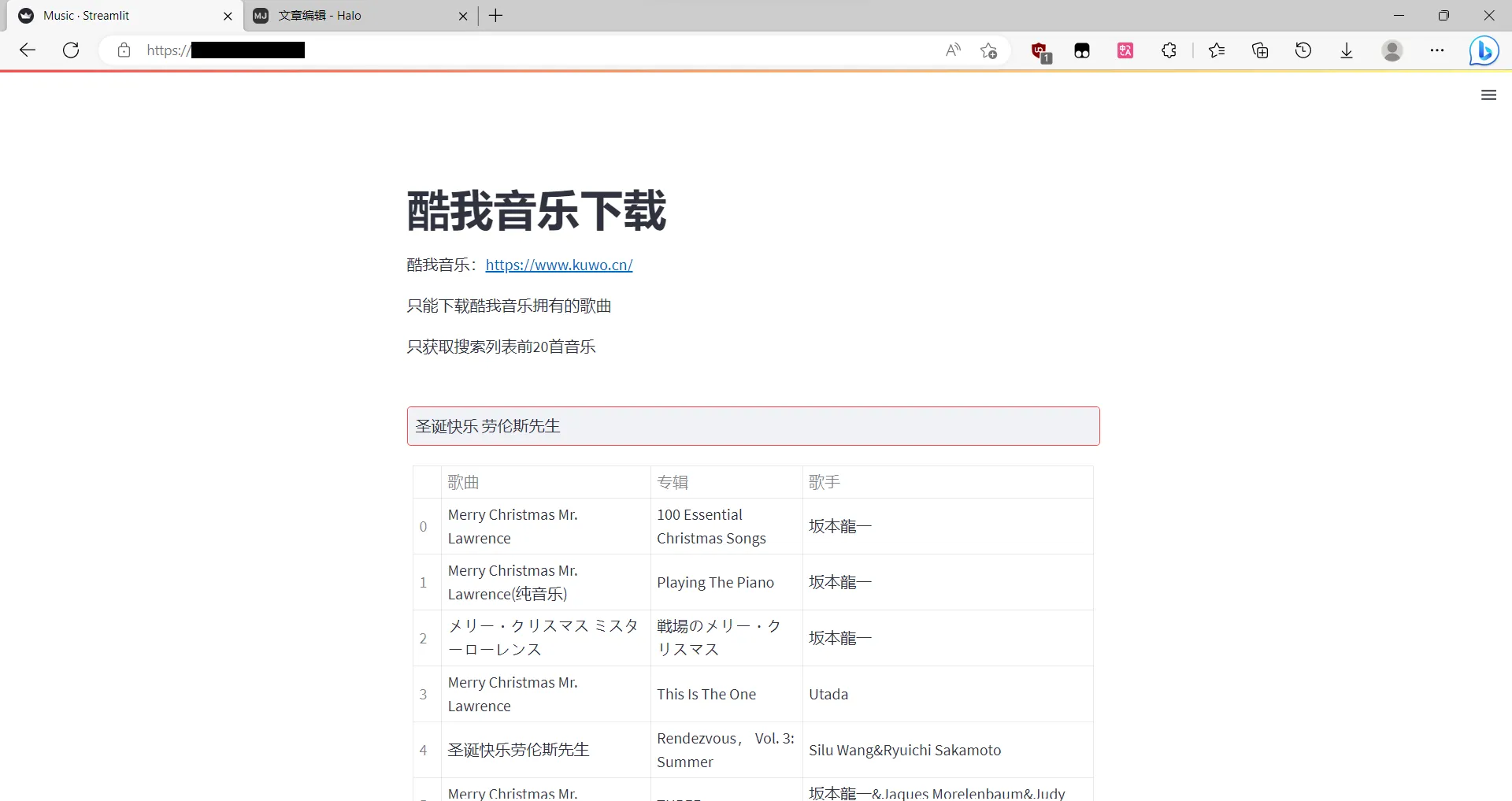
搜索后打印爬取到的前20首歌曲
向下翻用一个滑块选择序号对应的歌曲,从0开始,点击确定后显示歌曲的音频播放器和一个下载按钮
环境
系统 :pve lxc Debian 11
Python : 3.9.2
streamlit :1.22.0
beautifulsoup4 : 4.12.2
requests :2.28.2
代码
替换cookie和csrf,浏览器在酷我搜索界面按f12自行查找。
import requests
import streamlit as st
import os
from bs4 import BeautifulSoup
import re
from urllib.parse import quote
import pandas as pd
#传入mid和name下载歌曲并重命名
def music(name,mid):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.64'
}
url_base = 'https://www.kuwo.cn/api/v1/www/music/playUrl?mid=%s&type=mp3&httpsStatus=1'
url = url_base % mid
response = requests.get(url, headers=headers)
result = response.json()
play_url = result['data']['url']
play = requests.get(play_url, headers=headers)
with open(f'./file/{name}.mp3', 'wb') as f:
f.write(play.content)
#通过url获取歌名
def name_music(url):
detail = requests.get(url)
# mid = re.search(r'\d+', url).group()
html = BeautifulSoup(detail.content, 'html.parser')
name = html.find('span', class_='name').text.strip()
return name
#搜索返回表格
def search(sth):
url_base = "https://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key=%s&pn=1&rn=20&httpsStatus=1&reqId=5cf864c0-e8e9-11ed-a0c3-7751e26bbea4"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.68',
'Referer': 'https://www.kuwo.cn/search/list?key=' + quote(sth),
'Cookie': '-------------------------f12自己找-----------------------------',
'csrf': '--------------------------f12自己找-----------------------------'
}
url = url_base % sth
response = requests.get(url, headers=headers)
search_dick = response.json()
name_list = []
album_list = []
musicrid_list = []
artist_list = []
for song in search_dick['data']['list']:
name = song['name']
album = song['album']
artist = song['artist']
musicrid = song['musicrid']
artist_list.append(artist)
name_list.append(name)
album_list.append(album)
musicrid_list.append(musicrid)
mid_list = []
for musicrid in musicrid_list:
numbers = str(re.findall(r'\d+', musicrid))[2:-2]
mid_list.append(numbers)
df = pd.DataFrame(
{
'歌曲': name_list,
'专辑': album_list,
'歌手': artist_list,
'mid': mid_list
}
)
df_view = pd.DataFrame(
{
'歌曲': name_list,
'专辑': album_list,
'歌手': artist_list,
}
)
return df,df_view
st.title('酷我音乐下载')
st.write('酷我音乐:https://www.kuwo.cn/')
st.write('只能下载酷我音乐拥有的歌曲')
st.write('只获取搜索列表前20首音乐')
sth = st.text_input('',placeholder='青花瓷')
if not sth:
st.write('可以搜索:歌曲、专辑、作者等,可同时填入精确搜索')
st.write('输入完成点击其他地方或回车开始搜索')
else:
df,df_view = search(sth)
st.table(df_view)
num_songs = df.shape[0] - 1
song_num = st.slider('选择歌曲序号', 0, num_songs)
st.write(f'选择序号为{song_num}的歌曲')
if st.button('确定'):
mid = df['mid'][song_num]
url = 'https://www.kuwo.cn/play_detail/' + mid
name = name_music(url)
music(name,mid)
with open(f'./file/{name}.mp3', "rb") as file:
st.audio(file)
st.download_button(
label="下载音乐",
data=file,
file_name=f'{name}.mp3',
mime='audio/mp3'
)
os.remove(f'./file/{name}.mp3')
windows上运行不能删除服务端下载的音乐
保存至 music.py
运行:streamlit run music.py
后台运行:nohup streamlit run music.py &
查看进程:ps -le | grep streamlit
结束进程:kill pid